
Climate systems modeling, earthquake forecasting, vaccine development, materials design, drug discovery, stockpile stewardship and image recognition are among the many fields where HPC has made important contributions. However, even with the most advanced supercomputers, many of the problems in these fields remain intractable. The need to solve these problems, combined with the ever-increasing complexity of issues faced by our society, puts constant pressure on HPC centers to innovate and increase their computational power.
Several approaches are being adopted by HPC centers to innovate their infrastructure (see figure below). A popular choice is memory-driven computing, where each processor in a system is given access to an enormous reservoir of shared memory. This is in contrast to most of today’s systems where each processor is allocated its own limited amount of memory. The advantage of memory-driven computing is that it eliminates the need for each processor to send requests when looking for data held in another processor’s memory. This approach is particularly well-suited to big data and offers both performance and energy efficiency gains.
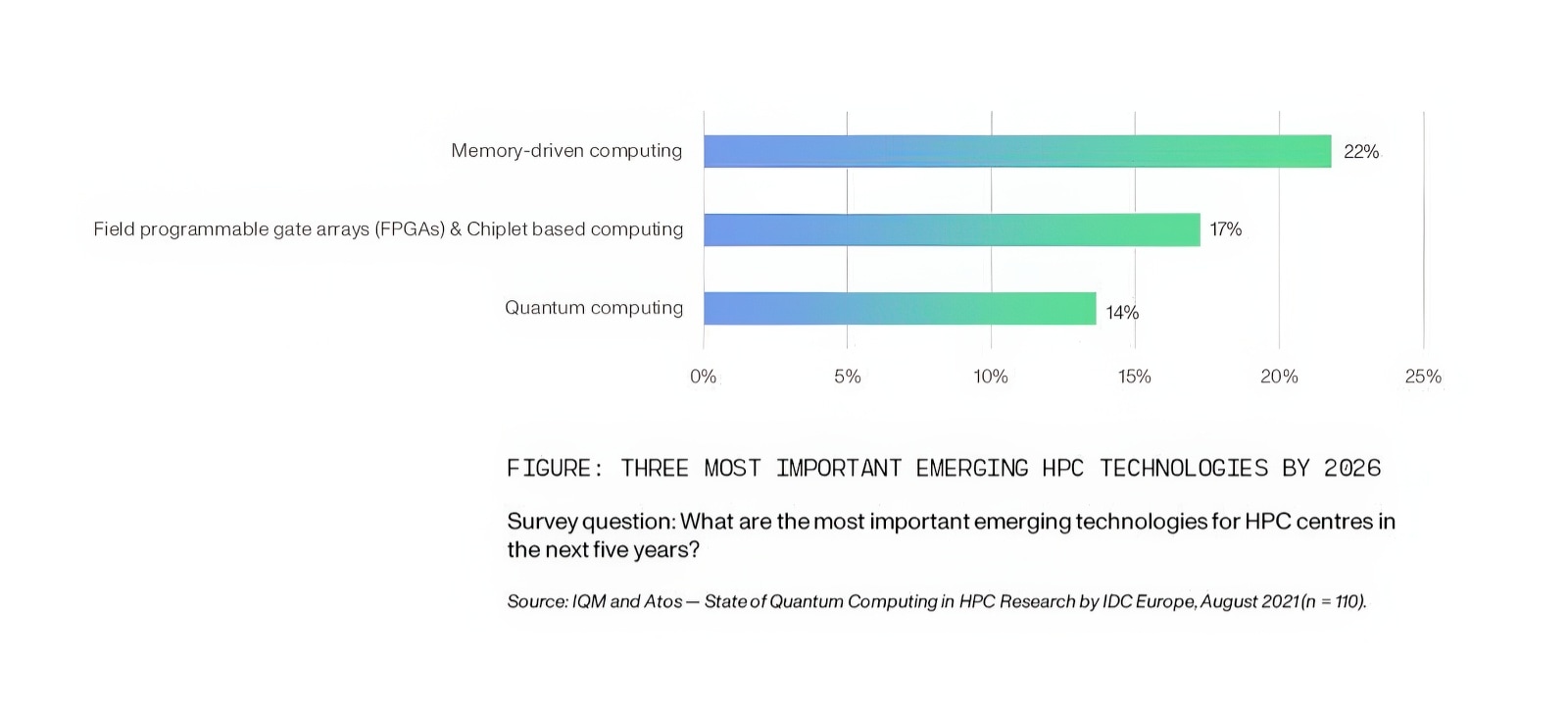
Another approach is to offer greater flexibility, control and customization at the hardware level. Both chiplets and field-programmable gate arrays (FPGAs) offer this. Chiplets are miniature integrated circuits with a specialized function that is a subset of what is found on a complete, traditional chip. Different chiplets can be combined in a variety of ways to achieve a desired functionality. The modularity that chiplets offer is one reason for their popularity. In the case of FPGAs, the flexibility is obtained through an array of programmable logical blocks with connections that can be reconfigured to achieve the required computational behavior. FPGAs are used to accelerate HPC due to their performance per watt advantage.
A radically new approach to innovate is through a completely different paradigm: quantum computing. In contrast to the modest increase in performance expected from the approaches described above, quantum computing offers the possibility of revolutionary breakthroughs, such as turning computationally inaccessible problems into tractable ones. For example, problems that would take too long to calculate on a classical (conventional) computer–because of the exponential or sub-exponential time complexity–could be calculated on a quantum computer within a reasonable amount of time (polynomial time).
Quantum computing is still in its infancy, but because of its potential to completely transform HPC, it is essential to create now a roadmap for how to integrate HPC with quantum computing. For this reason, IQM partnered with Atos and commissioned a survey, carried out by IDC Europe in August 2021, to evaluate the state of quantum computing in HPC (IQM and Atos — State of Quantum Computing in HPC Centers). A major takeaway from this survey is that HPC centers must create a long-term strategic plan to successfully integrate quantum computing into their workflow. In particular, the recommendation is to implement a three-step roadmap:
In this blog, we focus on the first step: gap analysis and quantum solution identification. Future blogs will discuss the second and third steps in this roadmap.
In the first step, HPC centers should begin by conducting a gap analysis. That is, each center should analyze the problems it is working on and find those for which the solutions offered by the present infrastructure of classical computers could be improved. In this context, the nature of the improvement will depend on the type of problem studied: it could be a shorter time-to-output, a higher accuracy of prediction or a gain in other performance metrics. The aim should be to make the gap analysis as concrete as possible. In this way, it will be easier to demonstrate the benefits of quantum computing and convince all stakeholders of the value of integrating classical HPC with quantum computing.
Some aspects of the gap analysis will depend on the nature of HPC centers. There are HPC centers that are tailored to specific-use cases or where the users focus on a small set of problem types (e.g., the interactions of biomolecules). For these centers, which are typically found in private companies, the improvement goals should be based on the specific cases or problem types being studied. For general-purpose HPC centers, which are often publicly-funded or offered as a service, the improvement goals should be aligned with existing HPC infrastructure in order to maintain maximum flexibility in terms of use-cases. However, even for the general-purpose centers, it is helpful to begin the analysis by considering the most common specific use-cases in order to ensure that the gap analysis remains concrete.
How should an HPC center choose which problems to target for improvement with quantum computing? In the long term, most computationally difficult problems will benefit from quantum computing once an appropriate algorithm is developed. However, in the absence of a universal quantum computer, how to choose the problems requires more thought because in the short term quantum computers will function as accelerators to classical machines, and therefore offer benefits only for specific types of problems. The flowchart below provides a way to identify such problems (adapted from “Towards a standard methodology for constructing quantum use cases” by N. Chancellor, R. Cumming and T. Thomas)
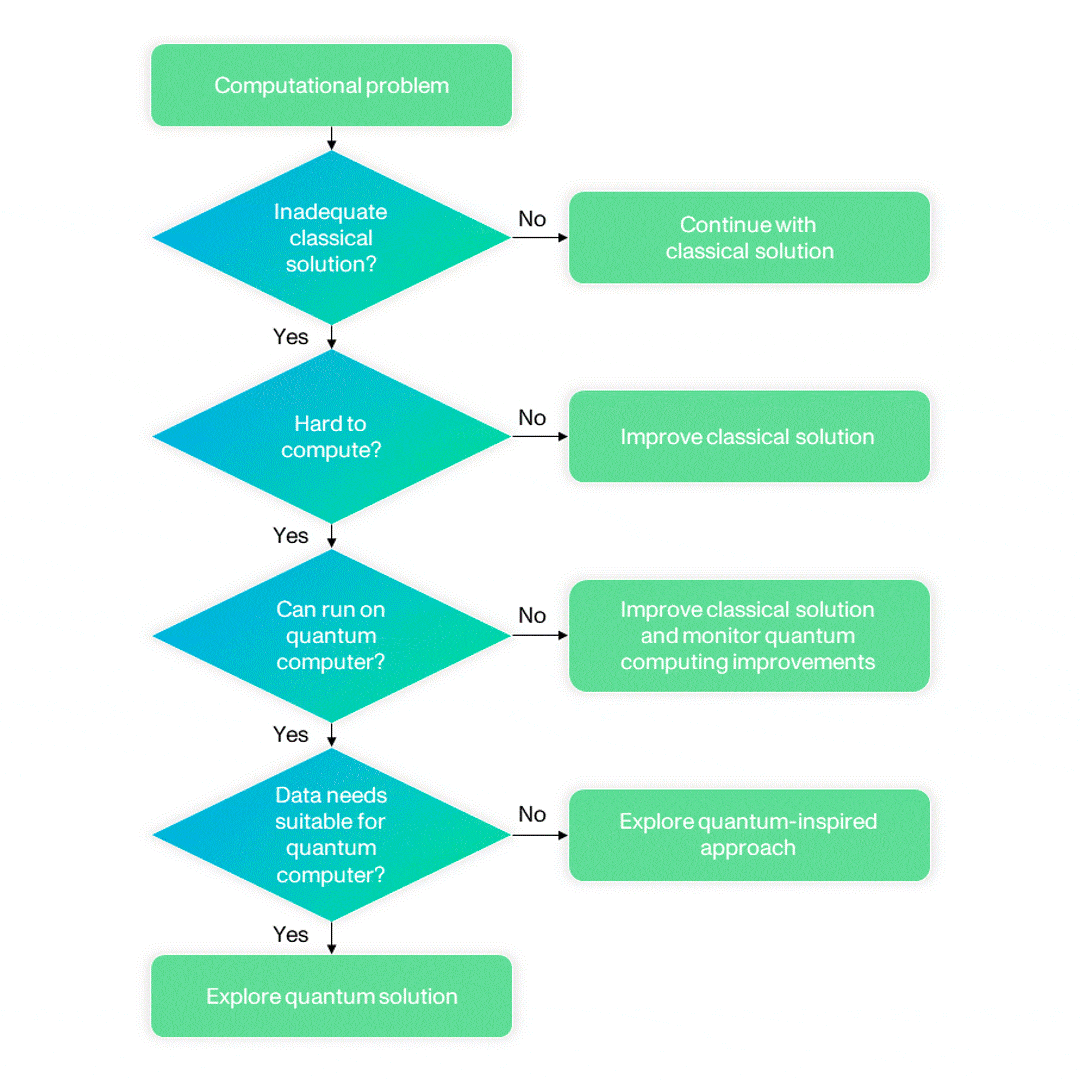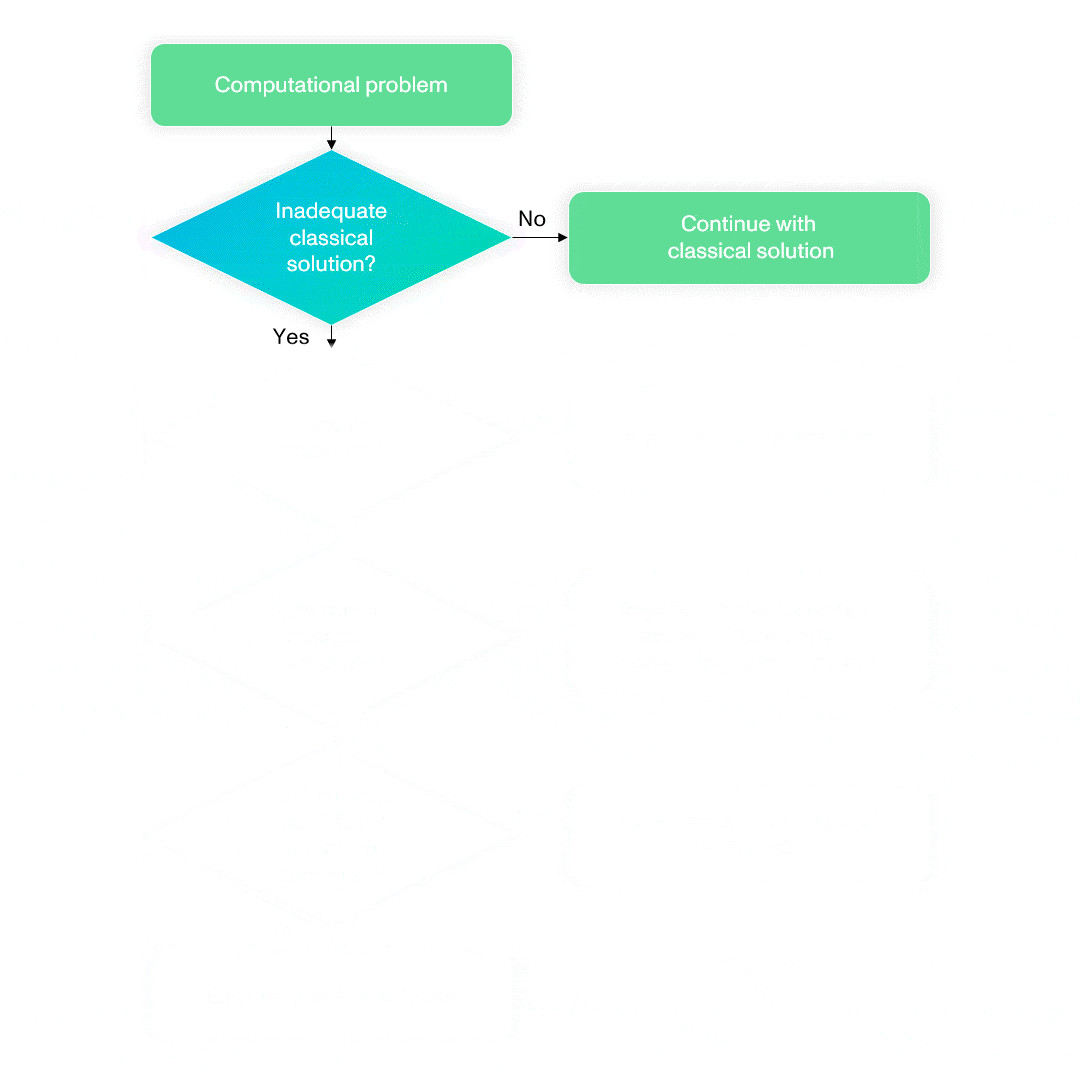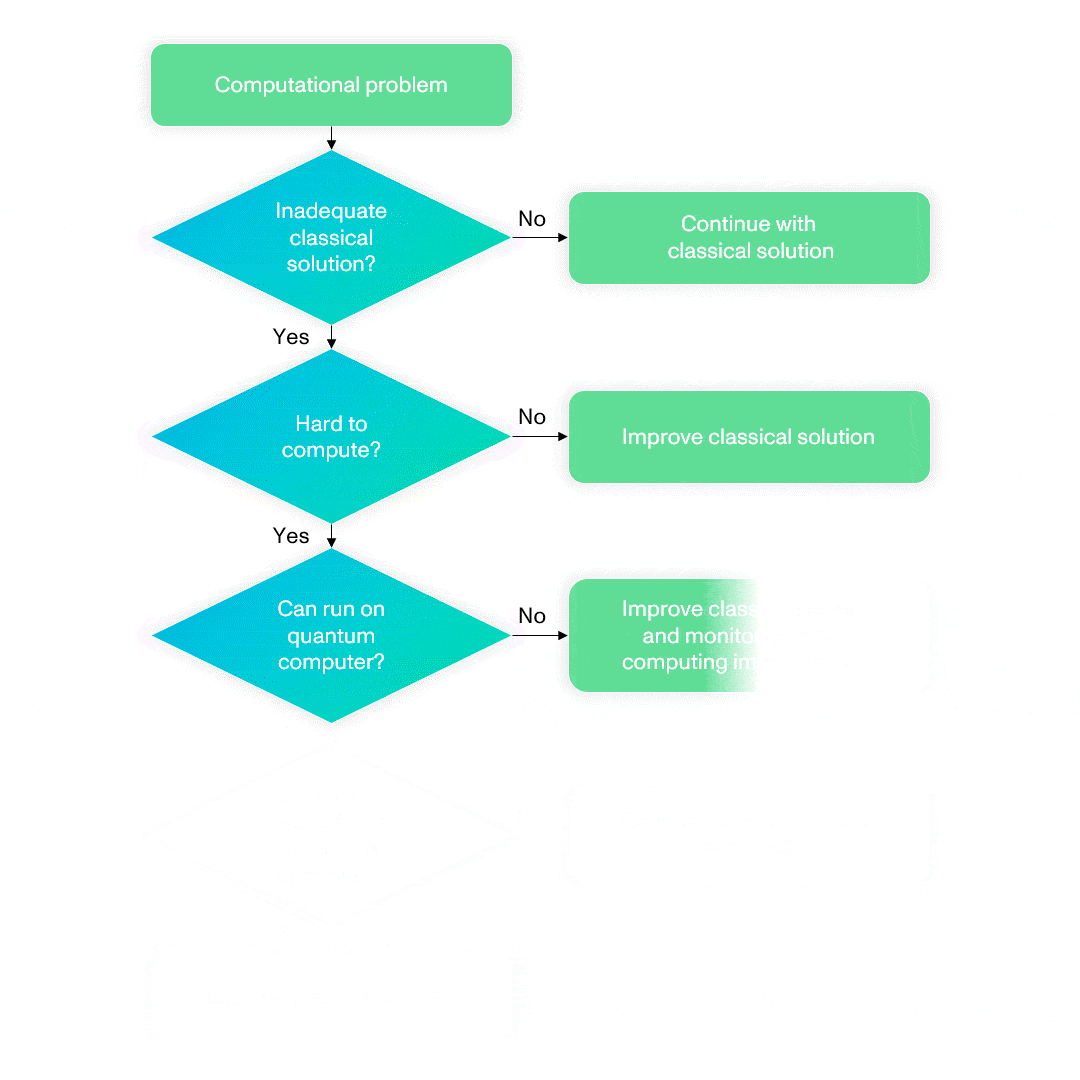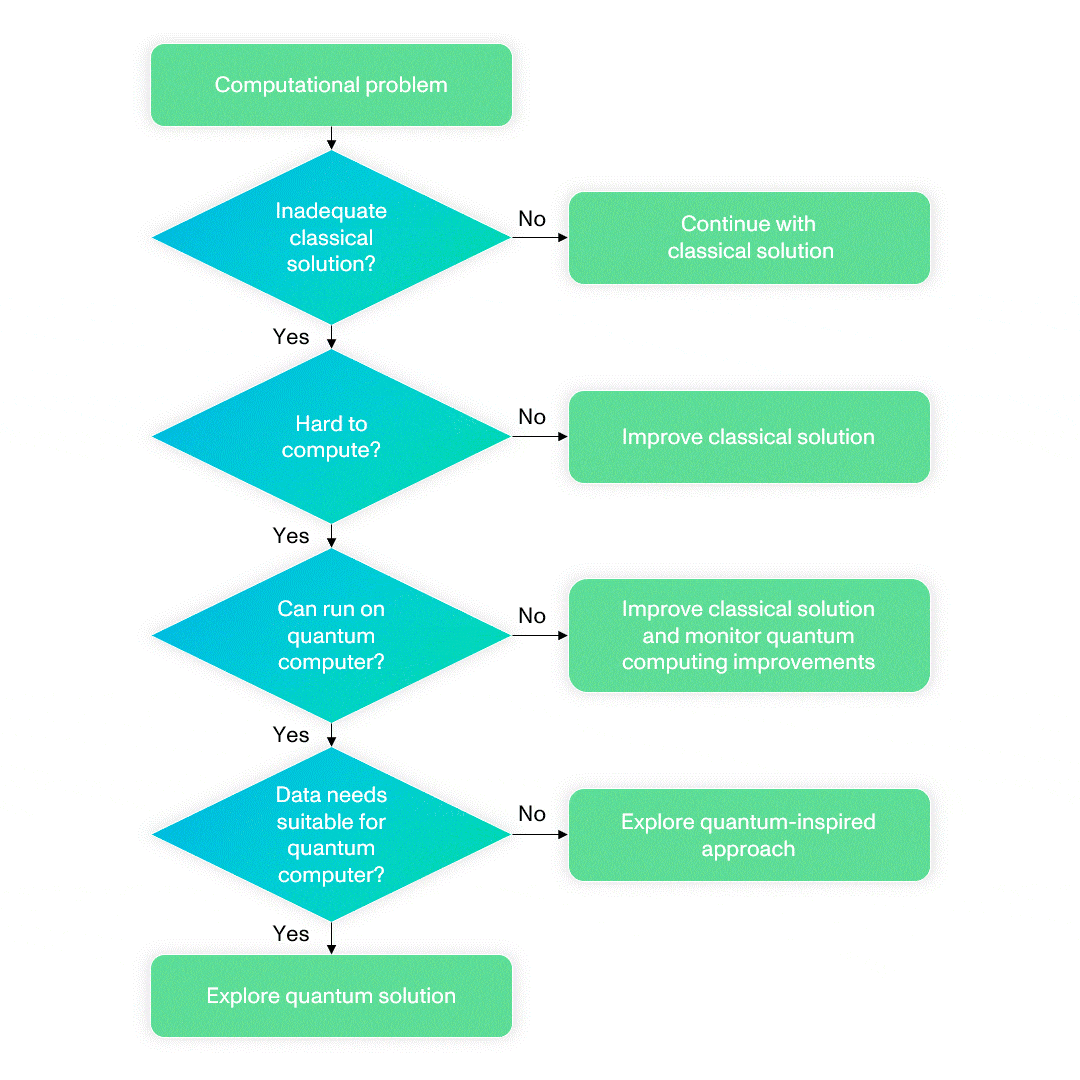
What are some of the specific problems that are ripe for improvement by bringing together HPC and quantum computing? Here are a few examples.
A. All-atom simulations of molecules in complex environments. Such systems include drug targets binding to a protein or a composite material in the presence of a solvent. Because these systems are studied at the atomic scale, they should be ideally simulated using quantum mechanics as quantum mechanics is the fundamental theory that provides the most accurate description of the physical properties of nature at the atomic scale.
However, to fully simulate millions of atoms using quantum mechanics is currently computationally prohibitive. The approximation usually made to render the simulation computationally feasible is to separate the problem into two pieces: most of the atoms are simulated classically (using Newton’s laws of motion with a suitable intermolecular potential) and only the critical part of the system (for example, the binding site of the protein) is simulated using quantum mechanics. Of course, even in this approximation, the quantum mechanical part is done with a classical computer which limits the size of the critical part of the system that can be simulated.
By integrating a quantum computer with HPC, the quantum mechanical part of the simulation can be carried out with a quantum computer. This should lead to higher accuracy since both the quantum computer and the part of the system it is simulating obey the same laws of quantum mechanics. Also, as quantum computers become more powerful, the number of atoms that can be simulated quantum mechanically is expected to increase significantly.

B. Modeling the behavior of large-scale systems. HPC is often used to model large-scale systems (many kilometers in size), such as the weather or earthquakes, in order to make accurate predictions. As part of the modeling, coupled differential equations with a large number of variables must be solved. Currently, the computation burden of solving partial differential equations in two or more dimensions, such as those characterizing fluid flow in petroleum reservoirs, is a challenge for HPC simulations.
There are several quantum algorithms for solving differential equations that can in principle reduce this computational burden. Just as with the simulations of molecular systems, the quantum computer can be used for part of the simulation—in this case, solving the differential equations—which is then integrated with the rest of the simulation that is carried out using classical HPC.

C. Optimization problems. Many industrial and financial problems, such as the location of sensors in an automobile or the pricing of financial instruments, can be formulated in terms of the minimization of some objective function. As the number of variables in these problems increases, solving an optimization problem using a classical computer becomes intractable because of the large time complexity. However, due to the inherent parallelism in quantum computers, it is possible to improve the sub-optimal solutions that classical computers find without incurring the cost of exponentially longer computation times.
As in the previous two examples, the optimization can be separated into classical and quantum parts. For example, the classical computer chooses the initial parameters, which are supplied to the quantum computer that prepares the trial state of the system based on these parameters and measures the energy of this trial state. The results are then fed back to the classical computer which uses the information to select a new set of parameters. The process is repeated until the desired convergence is reached.
Once the appropriate problems are identified, it is important for an HPC center to find a suitable quantum computing provider as a collaborator that can support the analysis of the problems and help with the formulation of objectives that the quantum computer should achieve. While many HPC centers are building their quantum computing skill set, others still do not have a sufficient knowledge base to integrate HPC with quantum computing. By working with an experienced collaborator, HPC centers can begin training their own research scientists and developers in quantum computing. And after the bringing together of HPC and quantum computing has begun, HPC centers can plan for the second step in the roadmap as will be discussed in the next blog.
